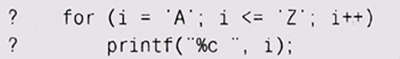|
|
|
| Загадочные числа Загадочные числа — это константы, размеры массивов, позиции символов и другие числовые значения, появляющиеся в программе непосредственно, как "буквальные константы". Давайте имена загадочным числам. В принципе нужно считать, что любое встречающееся в программе число, отличное от 0 и 1, является загадочным и должно получить собственное имя. Просто "сырые" числа в тексте программы не дают представления об их происхождении и назначении, затрудняя понимание и изменение программы. Вот отрывок из программы, которая печатает гистограмму частот букв на терминале с разрешением 24 X 80. Этот отрывок неоправданно запутан из-за целого сонма непонятных чисел:
Присвоив имена числам, имеющим принципиальное значение, мы облегчим понимание кода. Например, станет понятно, что число 3 берется из арифметического выражения (80-1)/26, а массив let должен иметь 26 элементов, а не 27 (иначе возможна ошибка его переполнения на единицу — из-за того, что экранные координаты индексируются, начиная с 1). Сделав еще пару усовершенствований, мы придем к следующему результату:
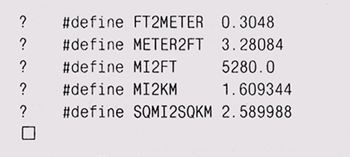
Определяйте числа как константы, а не как макросы. Программисты, пишущие на С, традиционно использовали для определения загадочных чисел директиву #def те. Однако препроцессор С — мощный, но несколько туповатый инструмент, а макросы — вообще довольно опасная вещь, поскольку они изменяют лексическую структуру программы. Пусть лучше язык делает свойственную ему работу. В С и C++ целые (integer) константы можно определять с помощью выражения en urn (которое мы и использовали в предыдущем примере). В C++ любые константы можно определять с помощью ключевого слова const: const int MAXROW = 24, MAXCOL = 80; В Java для этого служит слово final: static final int MAXROW = 24, MAXCOL = 80; В С также можно определять значения с помощью ключевого слова const, но эти значения нельзя использовать как границы массива, так что зачастую придется прибегать все к тому же enum. Используйте символьные, а не целые константы. Для проверки свойств символов должны использоваться функции из <ctype. h> или их эквиваленты. Если проверку организовать так: ? if (с >= 65 && с <= 90) ?....
if (с >= 'А' с <= 'Z') но и это может не принести желаемого результата, если буквы в имеющейся кодировке идут не по порядку или если в алфавите есть и другие буквы. Лучшее решение — привлечь на помощь библиотеку: if (isupper(c)) в С и C++ или if (Character. isllpperCase(c)) в Java. Сходный вопрос — использование в программе числа 0. Оно используется очень часто и в различных контекстах. Компилятор преобразует этр число в соответствующий тип, однако читателю гораздо проще понять роль каждого конкретного 0, если тип этого числа каждый раз обозначен явным образом. Так, например, стоит использовать (void * )0 или NULL для обозначения нулевого указателя в С, а ' \0' вместо просто 0 — для обозначения нулевого байта в конце строки. Другими словами, не пишите
Используйте средства языка для определения размера объекта. Не используйте явно заданного размера ни для каких типов данных — так, например, используйте sizeof (int) вместо прямого указания числа 2,4 и т.п. По сходным причинам лучше использовать sizeof(array[OJ) вместо sizeof (int) — меньше придется исправлять при изменении типа массива. Использование оператора sizeof избавит вас от необходимости выдумывать имена для чисел, обозначающих размер массива. Например, если написать char buf[1024]; то размер буфера хоть и станет "загадочным числом", от которого
мы предостерегали ранее, но зато оно появится только один раз — непосредственно
в описании. Может быть, и не стоит прилагать слишком большие усилия, чтобы
придумать имя для размера локального массива, но определенно стоит постараться
и написать код, который не нужно переписывать при изменении размера или
типа: char buf[] = new char[1024]; В С и C++ нет эквивалента этому полю, но для массива (не указателя), описание которого является видимым, количество элементов можно вычислить с помощью следующего макроса:
Здесь опять-таки размер массива задается лишь в одном месте, и при его изменении весь остальной код менять не придется. В данном макросе нет проблем с многократным вычислением аргумента, поскольку в нем нет никаких побочных эффектов, и на самом деле все вычисление происходит во время компиляции. Это пример грамотного использования макроса — здесь он делает то, чего не может сделать функция: вычисляет размер массива исходя из его описания. Упражнение 1-10 Как бы вы переписали приведенные определения, чтобы уменьшить число
потенциальных ошибок? |
|
|
|