|
|
|
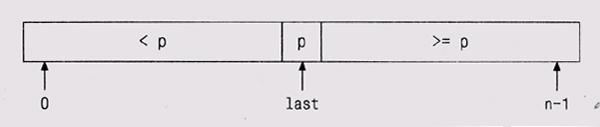
Сортировка Двоичный поиск работает только в том случае, если элементы отсортированы. Если по одному и тому же набору данных планируется неоднократный повторный поиск, то выгоднее один раз отсортировать данные, а затем использовать двоичный поиск. Если набор данных известен заранее, то он может быть отсортирован при написании программы и проинициализирован во время компиляции. Иначе придется сортировать его во время выполнения программы. Один из самых лучших алгоритмов сортировки — быстрая сортировка (quicksort), которая была придумана в 1960 году Чарльзом Хоаром (С. A. R. Ноаге). Быстрая сортировка — замечательный пример того, как можно избежать лишних вычислений. Она работает при помощи разделения массива на большие и маленькие элементы:
Когда этот процесс закончится, то массив будет отсортирован. Быстрая сортировка работает быстро, потому что, как только мы узнаем, что элемент меньше, чем разделитель, нам уже не нужно его сравнивать с большими элементами; аналогично, большие элементы не сравниваются с маленькими. Поэтому данный алгоритм существенно быстрее, чем такие простые методы сортировки, как сортировка вставкой или пузырьком, когда каждый элемент сравнивается напрямую со всеми остальными. Алгоритм быстрой сортировки практичен и эффективен; он хорошо изучен, и существует множество его вариаций. Версия, которую мы здесь представим, является одной из самых простых реализаций, но, конечно, далеко не самой быстрой. Наша функция quicksort сортирует массив целых чисел:
Насколько быстро работает быстрая сортировка? В наилучшем случае
Данный процесс продолжается примерно Iog2 n раз, поэтому общее время работы в лучшем случае пропорционально п + 2 X и/2 + 4 х и/4 + + 8 X п/8 ... (Iog2 и слагаемых), что равно п log? п. В среднем алгоритм работает совсем не намного дольше. Обычно принято использовать именно двоичные логарифмы, поэтому мы можем сказать, что быстрая сортировка работает пропорционально n long. Эта демонстрационная реализация быстрой сортировки наиболее прозрачна, но у нее есть одна слабина. Если каждый выбор разделителя разбивает массив на две примерно одинаковые группы, то наш анализ корректен, однако если разделение слишком часто происходит неровно, то время работы будет расти скорее как п1. В нашей реализации в качестве разделителя берется случайный элемент, чтобы уменьшить шанс того, что плохие входные данные приведут к слишком большому количеству неровных разбиений массива. Но если все входные значения одинаковы, то наша реализация за каждый проход будет отделять только один элемент, поэтому время работы будет расти как п2. Поведение некоторых алгоритмов сильно зависит от входных данных. Неправильный или неудачный ввод может заставить в среднем хороший алгоритм работать крайне медленно или использовать огромное количество памяти. В случае быстрой сортировки, хотя простые реализации вроде нашей иногда могут работать медленно, более продуманные реализации способны уменьшить шанс патологического поведения почти до нуля. |
|
|
|