Создание структуры данных в языке С
Начнем с реализации на С. Для начала надо задать некоторые константы:

В этом описании определяются количество слов в префиксе (NPREF), размер
массива хэш-таблицы (NHASH) и верхний предел количества генерируемых слов
(MAXGEN). Если NPREF — константа времени компиляции, а не переменная времени
исполнения, то управление хранением упрощается. Мы задали очень большой
размер массива, поскольку программа должна быть способна воспринимать
очень большие документы, возможно, даже целые книги. Мы выбрали NHASH
= 4093, так что если во введенном . тексте имеется 10 000 различных префиксов
(то есть пар слов), то среднестатистическая цепочка будет весьма короткой
— два или три префикса. Чем больше размер, тем короче будет ожидаемая
длина цепи и, следовательно, тем быстрее будет осуществляться поиск. Эта
программа создается для развлечения, поэтому производительность ее не
критична, однако если мы сделаем слишком маленький массив, то программа
не сможет обработать текст ожидаемого размера за разумное время; если
же сделать его слишком большим,'он может не уложиться в имеющуюся память.
Префикс можно хранить как массив слов. Элементы хэш-таблицы будут представлены
как тип данных State, ассоциирующий список Suffix с префиксом:

Графически структура данных выглядит так:
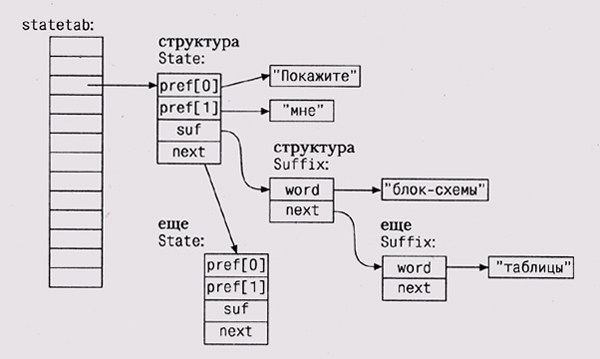
Нам потребуется хэш-функция для префиксов, которые являются массивами
строк. Нетрудно преобразовать хэш-функцию из главы 2, сделав цикл по строкам
в массиве, таким образом хэшируя конкатенацию этих строк:


Выполнив схожим образом модификацию алгоритма lookup, мы завершим реализацию
хэш-таблицы:

Обратите внимание на то, что lookup не создает копии входящей строки при
создании нового состояния, просто в sp->pref [ ] 'сохраняются указатели.
Те, кто использует вызов lookup, должны гарантировать, что впоследствии
данные изменены не будут. Например, если строки находятся в буфере ввода-вывода,
то перед тем, как вызвать lookup, надо сделать их копию; в противном случае
следующие куски вводимого текста могут перезаписать данные, на которые
ссылается хэш-таблица. Необходимость решать, кто же владеет совместно
используемыми ресурсами, возникает достаточно часто. Эту тему мы подробно
рассмотрим в следующей главе.
Теперь нам надо прочитать файл и создать хэш-таблицу:
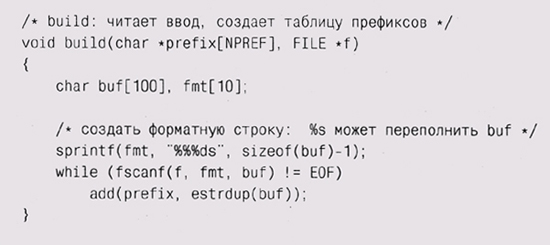
Необычный вызов sprintf связан с досадной проблемой, присущей f scant,
— если бы не эта проблема, функция f scanf идеально подошла бы для нашего
случая. Все дело в том, что вызов fscanf с форматом %s считывает следующее
ограниченное пробелами слово из файла в буфер, но без проверки его длины:
слишком длинное слово может переполнить входной буфер, что приведет к
разрушительным последствиям. Если буфер имеет размер 100 байтов (что гораздо
больше того, что ожидаешь встретить в нормальном тексте), мы можем использовать
формат %99s (оставляя один байт на заключительный ' \0'), что будет означать
для fscanf приказ остановиться после 99 байт. Тогда длинное слово окажется
разбитым на части, что некстати, но вполне безопасно. Мы могли бы написать
? enum { BUFSIZE = 100 };
? char fmtrj = "%99s"; /1 BUFSIZE-1 ./
однако это потребовало бы двух констант для одного, довольно произвольного
значения — размера буфера; обе эти константы пришлось бы поддерживать
в непротиворечивом состоянии. Проблему можно решить раз и навсегда, создавая
форматную строку динамически — с помощью sprintf, и именно так мы и поступили.
Аргументы build — массив prefix, содержащий предыдущие NPREF введенных
слов и указатель FILE. Массив prefix и копия введенного слова передаются
в add, которая добавляет новый элемент в хэш-таблицу и обновляет префикс:

Вызов memmove — идиоматический способ удаления из массива. В префиксе
элементы с 1 по NPREF-1 сдвигаются вниз на позиции с 0 по NPREF-2, удаляя
первое слово и освобождая место для нового слова в конце.
Функция addsuf fix добавляет новый суффикс:

Мы разделили процесс обновления состояния на две функции — add просто
добавляет суффикс к префиксу, тогда как addsuffix выполняет тесно связанное
с реализацией действие — добавляет слово в список суффиксов. Функция add
вызывается из build, но addsuffix используется только изнутри add — это
та часть кода, которая может быть впоследствии изменена, поэтому лучше
выделить ее в отдельную функцию, даже если вызываться она будет лишь из
одного места.
|


