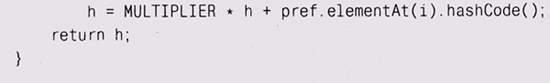|
|
|
Java Вторую реализацию алгоритма markov мы создадим на языке Java. Объектно-ориентированные языки вроде Java заставляют нас обращать особое внимание на взаимодействие между компонентами программы. Эти компоненты инкапсулируются в независимые элементы данных, называемые объектами или классами; с ними ассоциированы функции, называемые методами. Java имеет более богатую библиотеку, чем С. В частности, эта библиотека включает в себя набор классов-контейнеров (container classes) для группировки существующих объектов различными способами. В качестве примера можно привести класс Vector, который представляет собой динамически растущий массив, где могут храниться любые объекты типа Object. Другой пример— класс Hashtable, с помощью которого можно сохранять и получать значения одного типа, используя объекты другого типа в качестве ключей. В нашем приложении экземпляры класса Vector со строками в качестве объектов — самый естественный способ хранения префиксов и суффиксов. Так же естественно использовать и класс Hashtable, ключами в котором будут векторы префиксов, а значениями — векторы суффиксов. Конструкции подобного рода называются отображениями (тар) префиксов на суффиксы; в Java нам не потребуется в явном виде задавать тип State, поскольку Hashtable неявным образом сопоставляет префиксы и суффиксы. Этот дизайн отличается от версии С, где мы создавали структуры State, в которых соединялись префиксы и списки суффиксов, а для получения структуры State использовали хэширование префикса. Hashtable предоставляет в наше распоряжение метод put для хранения пар ключ-значение и метод get для получения значения по заданному ключу:
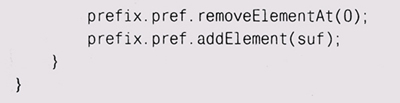
Функция add получает из хэш-таблицы вектор суффиксов для текущего префикса; если их не существует (вектор есть null), add создает новый вектор и новый префикс для сохранения их в таблице. В любом случае эта функция добавляет новое слово в вектор суффиксов и обновляет префикс, удаляя из него первое слово и добавляя в конец новое.
Функция генерации похожа на аналогичную из программы на С, однако она получается несколько компактнее, поскольку может случайным образом выбирать индекс элемента вектора вместо того, чтобы в цикле обходить весь список.
Метод hashCode создает отдельно взятое хэш-значение, комбинируя набор значений hashCode для элементов вектора:
Программа на Java гораздо меньше, чем ее аналог на С, при этом больше деталей проработано в самом языке — очевидными примерами являются классы Vector и Hashtable. В общем и целом управление хранением данных получилось более простым, поскольку вектора растут, когда' нужно, а сборщик мусора (garbage collector — специальный автоматический механизм виртуальной машины Java) сам заботится об освобождении неиспользуемой памяти. Однако для того, чтобы использовать класс Hashtable, нам пришлось-таки самим писать функции hashCode и equals, так что нельзя сказать, что язык Java заботился бы обо всех деталях. Сравнивая способы, которыми программы на С и Java представляют < и обрабатывают одни и те же структуры данных, следует отметить, что в версии на Java лучше разделены функциональные обязанности. При таком подходе нам, например, не составит большого труда перейти от использования класса Vector к использованию массивов. В версии С каждый блок связан с другими блоками: хэш-таблица работает с массивами, которые обрабатываются в различных местах; функция lookup четко ориентирована на конкретное представление структур State и Suffix; размер массива префиксов вообще употребляется практически всюду. Пропустив эту программу с исходным (химическим) текстом и форматируя сгенерированный текст с помощью процедуры f mt, мы получили следующее: % Java Markov <j r^cheinistry. txt | fmt Wash the blackboard.
Перепишите Java-версию markov так, чтобы использовать массив вместо класса Vector для префикса в классе Prefix. |
|
|
|