|
|
|
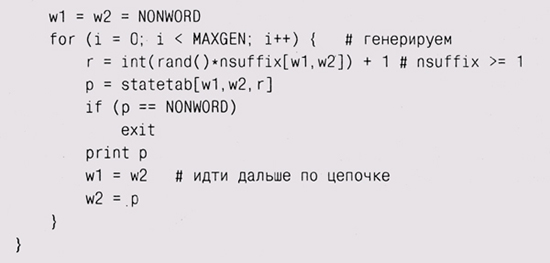
AWK и PERL Чтобы завершить наши упражнения, мы написали программу еще и на двух популярных языках скриптов — Awk и Perl. В них есть возможности, необходимые для нашего приложения, — ассоциативные массивы и методы обработки строк. Ассоциативный массив (associative array) — это подходящий контейнер для кэш-таблицы; он выглядит как простой массив, но его индексами являются произвольные строки, или числа, или наборы таких элементов, разделенных запятыми. Это разновидность отображения данных одного типа в данные другого типа. В Awk все массивы являются ассоциативными; в Perl есть как массивы, индексируемые стандартным образом, целочисленными индексами, так и ассоциативные массивы, которые называются "хэшами" (hashes), — из их названия сразу становится ясен способ их внутренней реализации. Предлагаемые версии на Awk и Perl рассчитаны только на работу с префиксами длиной в два слова.
Действие — это блок выражений, заключенный в фигурные скобки. В Awk-версии в блоке BEGIN инициализируется префикс и пара других переменных. Следующий блок не имеет образца, поэтому он по умолчанию вызывается для каждой новой строки ввода. Awk автоматически разделяет каждую вводимую строку на поля (ограниченные пробелами слова), имеющие имена от $1 до $NF; переменная NF — это количество полей. Выражение Statetab[w1,w2,++nsuffix[w1,w2]] = $i создает отображение префиксов в суффиксы. Массив nsuffix считает суффиксы, а элемент nsuf f ix[w1, w2] считает количество суффиксов, ассоциированных с префиксом. Сами суффиксы хранятся в элементах массива statetab[w1,w2, 1], statetab[w1, w2, 2] и т. д. Блок END вызывается на выполнение после тогсц как весь ввод был счи-1 тан. К этому моменту для каждого префикса существует элемент nsuffix, содержащий количество суффиксов, и, соответственно, существует именно столько элементов statetab, содержащих сами суффиксы. Версия Perl выглядит похожим образом, но в ней для хранения суффиксов используется безымянный массив, а не третий индекс; для обновления же префикса используется множественное присваивание. В Perl для обозначения типов переменных применяются специальные символы: $ обозначает скаляр, @ — индексированный массив, квадратные скобки [ ] используются для индексации массивов, а фигурные скобки { } — для индексации хэшей.
Как и в предыдущей программе, отображение хранится при помощи переменной statetab. Центральным моментом программы является выражение push(@{$statetab{$w1}{$w2}}, $_);
которое дописывает новый суффикс в конец (безымянного) массива, хранящегося в statetab{$w1}{$w2). На этапе генерации $statetab{$w1}{$w2} является ссылкой на массив суффиксов, a$suf->[$r] указывает на суффикс, хранящийся под номером r. Программы и на Awk, и на Perl гораздо короче, чем любая из трех предыдущих версий, но их тяжелее адаптировать для обработки префиксов, состоящих из произвольного количества слов. Ядро программ на С и C++ (функции add и generate) имеет сравнимую длину, но выглядит более понятно. Тем не менее языки скриптов нередко являются хорошим выбором для экспериментального программирования, для создания прототипов и даже для производственного использования в случаях, когда время счета не играет большой роли. Упражнение 3-7 Попробуйте преобразовать приложения на Awk и Perl так, чтобы они могли обрабатывать префиксы произвольной длины. Попробуйте определить, как это скажется на быстродействии программ. |
|
|
|