|
|
|
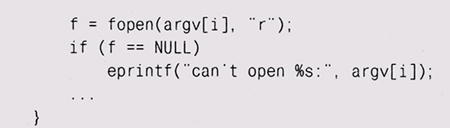
Abort, Retry, Fail? В предыдущих главах мы использовали для обработки ошибок функции вроде eprintf и estrdup — просто выводили некие сообщения перед тем, как прервать выполнение программы. Например, функция eprintf ведет себя так же, как fprintf (stderr, . . .), но после вывода сообщения выходит из программы с некоторым статусом ошибки. Она использует заголовочный файл <stdarg. h> и библиотечную функцию vfprintf для вывода аргументов, представленных в прототипе многоточием (...). Использование библиотеки stdarg должно быть начато вызовом va_start и завершено вызовом va__end. Мы еще вернемся к этому интерфейсу в главе 9.
Сходным образом работает est rdup: она пытается создать копию строки и, если памяти для этого не хватает, завершает программу с сообщением об ошибке (с помощью eprintf):
Эти функции описаны в заголовочном файле eprintf. h:
markov: can't open psalm.txt: No such file or directory Мы считаем эти "оберточные" функции вполне подходящими для наших собственных программ, поскольку они унифицируют обработку ошибок; кроме того, само их присутствие вдохновляет на поиск ошибок. Ничего сложного или особо выдающегося в них нет, так что вы можете запросто придумать для себя какие-то более подходящие варианты. Представим теперь, что вместо создания функций для собственного использования нам надо разработать библиотеку, с которой будут работать другие программисты. Что должна делать функция из этой библиотеки при возникновении ошибки? Те функции, что мы только что написали, выводят сообщение и умирают. Для многих программ, особенно для небольших самостоятельных утилит, такое поведение может'быть вполне приемлемым. Для других же программ простой выход не годится, поскольку при этом другие части программы лишаются возможности хотя бы попытаться вернуться в нормальное состояние; характерным примером являются текстовые редакторы, — в них стоит приложить максимум усилий для сохранения редактируемого документа. В некоторых ситуациях библиотечные функции не должны даже выдавать никакого сообщения, поскольку существуют системы, где такое сообщение будет мешать отображению полезной информации или же, наоборот, просто сгинет бесследно. Для подобных случаев полезно записывать сообщения в некий отдельный журнальный файл (log file), который можно просматривать независимо. Обнаруживайте ошибки на низком уровне, обрабатывайте на высоком. Существует общий принцип: ошибки должны обнаруживаться на самом низком уровне, какой только возможен; обрабатывать же их надо на высоком уровне. В большинстве случаев определять способ обработки ошибки должен вызывающий код, а не вызываемый. Библиотечные функции могут помочь в этом, обеспечивая приемлемую реакцию при сбоях, — например, при получении несуществующего поля в качестве аргумента не прерывать работу всей программы, а возвращать NULL. Или, как в csvgetline, возвращать NULL вне зависимости от того, сколько раз эта функция была вызвана после достижения конца файла. Не всегда очевидно, какие же значения должны возвращаться при ошибках; мы уже сталкивались с проблемой возвращаемого значения у функции csvgetline. Хотелось бы, конечно, возвращать как можно более содержательную информацию, но при этом в такой форме, чтобы остальная часть программы могла использовать ее без труда. В С, C++ и Java это значит, что информация должна возвращаться в качестве результата функции и, возможно, в значениях параметров-ссылок (указателей). Многие библиотечные функции умеют различать обычные значения и специальные значения ошибок. Функции ввода типа getcha r возвращают значение, конвертируемое в char для нормальных данных, и некоторое неконвертируемое в char значение, например EOF, для обозначения конца файла или ошибки. Этот механизм, однако, не работает, если функция может возвращать любые значения из возможного диапазона. Например, математические функции вроде log могут возвращать любое число с плавающей точкой. В стандарте IEEE для чисел с плавающей точкой предусмотрено специальное значение NaN ("not a number" — не число), означающее ошибку, — это значение и возвращается функциями в случае ошибки. Некоторые языки, такие как Perl и Tel, предоставляют несложный способ группировки двух и 0олее значений в кортеж (tuple). В таких языках значение функции и код ошибки можно без проблем передавать совместно. В C++ STL имеется тип данных pai r, который можно использовать таким же образом. Хотелось бы, по возможности, уметь различать исключительные значения типа конца файла или кода ошибок, а не запихивать их все в какое-то одно значение. Если значения нельзя разделить сразу же, можно поступить таким образом: возвращать одно значение для всех видов исключительных ситуаций и создать дополнительную функцию, которая бы возвращала дополнительную информацию об ошибке. Именно такой подход используется в Unix и стандартной библиотеке С: многие системные вызовы и библиотечные функции возвращают в случае ошибки -1 и при этом устанавливают глобальную переменную errno; функция strerror возвращает строку, соответствующую номеру ошибки. В нашей системе программа
nаnОхЮОООООО 33 Domain error Обратите внимание на то, что errno должна быть предварительно очищена (как в приведенной программе), тогда при возникновении ошибки она установится в некоторое ненулевое значение. Используйте исключения только для исключительных ситуаций. В некоторых языках для отлова нестандартных ситуаций и восстановления после них имеется специальный механизм исключений, или исключительных ситуаций (exceptions); таким образом предоставляется альтернативный способ управления работой программы при возникновении каких-либо проблем. Исключения не следует использовать для обработки обычных возвращаемых значений. Так, при чтении файла рано или поздно будет достигнут его конец; это должно обрабатываться посредством возвращаемого значения, а не исключения. Рассмотрим такой фрагмент, написанный на Java:
Этот цикл считывает символы, пока не будет достигнут конец файла — ожидаемое событие, которое функция read отмечает возвратом значения -1. Однако, если файл не может быть открыт, возникает (или, как принято говорить, возбуждается) исключение, а не установка переменной in в null, как это было бы сделано в С или C++. Наконец, если в блоке t ry происходит какая-то другая ошибка ввода, также возбуждается исключение, обрабатываемое в блоке lOException. Не стоит злоупотреблять исключениями: они сильно видоизменяют управляющую логику, что ведет к появлению достаточно сложных логических конструкций — потенциальных слабых мест программы. Вряд ли при неудачной попытке открыть файл, например, стоит возбуждать исключение. Последние лучпф оставить для действительно непредвиденных случаев вроде отсутствия свободного места на диске или.ошибок арифметики с плавающей точкой. В С пара функций — setjmp и longjmp — предоставляет возможность реализовать механизм исключений на гораздо более низком уровне, но это настолько сложно, что мы не будем описывать, как это сделать. Как насчет восстановления ресурсов при возникновении ошибки? Должна ли библиотека предпринимать попытки такого восстановления, если что-то идет не так, как надр? Как правило, нет, однако очень неплохо предусмотреть какой-то механизм, позволяющий удостовериться, что информация сохранилась в максимально корректной форме. Естественно, неиспользуемое пространство памяти должно быть высвобождено. Если же к каким-то, переменным еще возможен доступ, они должны быть установлены в осмысленные значения. Распространенной причиной ошибок является использование указателя на уже освобожденную память. Чтобы не попасться на эту удочку, достаточно в коде обработки ошибки, который высвобождает что-то, установить указатель, адресующийся к этому чему-то, в ноль. Функция reset во второй версии библиотеки CSV как раз и являлась нашей попыткой преодолеть некоторые из описанных проблем. Обобщая же все вышесказанное, отметим: надо добиваться того, чтобы библиотека оставалась пригодна к использованию даже после возникновения ошибки. |
|
|
|