|
|
|
Автоматизация тестирования Осуществлять тестирование вручную — скучно и ненадежно: при нормальном подходе вам потребуется прогнать множество тестов, перебрать множество вариантов ввода и сравнить множество результатов. Так что тестированием должны заниматься программы: они не устают и не отвлекаются от работы. Стоит потратить время на написание кода простейшей программы или просто скрипта, который включает все тесты, и все тестирование сможет выполниться от (буквально или фигурально) простого нажатия кнопки. Чем проще будет запуск тестирования, тем реже вы станете пренебрегать им из-за спешки. Мы написали набор тестовых утилит, которыми протестировали все программы, созданные для этой книги; этот же набор мы запускали после внесения любых изменений; некоторые утилиты запускались у нас автоматически после каждой успешной компиляции. Автоматизируйте возвратное тестирование. Одной из основных форм автоматизации является возвратное тестирование (regression testing), при котором выполняется последовательность тестов, сравнивающих очередную новую версию программы с предыдущей. При исправлении ошибок зачастую проверяются только собственно исправленные недочеты, при этом не принимается в расчет возможность внесения новых ошибок. Основное назначение возвратного тестирования — убедиться в том, что поведение программы изменилось только в предусмотренных рамках. В некоторых системах имеется большой арсенал средств, облегчающих подобную автоматизацию; языки скриптов позволяют писать короткие сценарии для запуска последовательностей тестов. В Unix утилиты сравнения файлов вроде cliff и стр дают возможность отслеживать изменения вывода, sort группирует схожие элементы, дгер фильтрует вывод тестов, we, sum и f req подсчитывают статистику вывода. С помощью этих утилит можно без труда создать подходящие к случаю тестовые оснастки — слабоватые, возможно, для больших проектов, но вполне пригодные для программ, создающихся одним или несколькими программистами. Ниже приведен скрипт для возвратного тестирования программы ka. (от killer application). Этот скрипт выполняет старую (old_ka) и новую (new_ka) версии программы на большом наборе тестовых файлов данных и выдает сообщения обо всех случаях, когда результаты оказались не идентичными. Скрипт написан для оболочки Unix, но его можно просто модифицировать под Perl или другой язык скриптов:
Аргумент -s заставляет стр возвращать результат прохождения теста и ничего не выводить. Если сравниваемые файлы оказываются эквивалентными, стр возвращает результат "истина", тогда ! стр оказывается "ложью", и, стало быть, ничего не печатается. Однако, если файлы вывода старой и новой версий различаются, стр возвращает значение "ложь", и выводится имя файла и предупреждение. При регрессивном тестировании предполагается, что предыдущая версия работала правильно. Это должно быть изначально (для первой версии) тщательнейшим образом проверено, поскольку, если ошибочный ответ каким-то образом проникает в систему возвратного тестирования, его очень трудно вычислить и, кроме того, все последующие версии программы будут обречены на его повторение. Поэтому хорошей практикой следует признать периодическую проверку самого возвратного теста. Создавайте замкнутые тесты. В дополнение к возвратным тестам полезно использовать и замкнутые тесты, которые содержат в себе и вводимые данные, и ожидаемые результаты. Здесь может оказаться поучительным наш опыт в тестировании программ на Awk. Многие конструкции языка тестируются посредством запуска крошечных программ на различных входных данных и проверкой выводимых результатов. Приведенный кусок взят из большого набора разнообразных тестов, он проверяет некоторое хитроумное инкрементное выражение. Тест запускает очередную версию программы (newawk), записывает ее выходные результаты в файл, правильные ответы записывает в другой файл с помощью команды echo, файлы сравнивает и в случае их различия сообщает об ошибке.
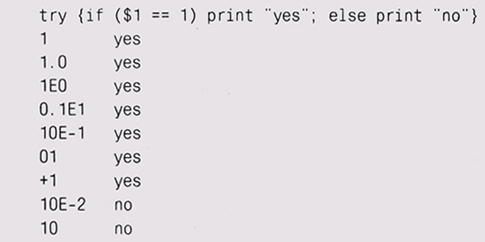
Иногда большой набор тестов можно создать без особых усилий. Для простых выражений мы создали небольшой специализированный язык описания тестов, вводимых данных и ожидаемых результатов. Вот небольшая последовательность, тестирующая некоторые способы представления числового значения 1 в Awk:
Программа на Awk (а на чем же еще?) преобразует каждый тест в полноценную же программу на Awk, далее пропускает через него каждый возможный вариант ввода и сравнивает полученные результаты с ожидаемыми; сообщается только о тех случаях, когда результат сравнения окажется отрицательным. Схожие механизмы используются для тестирования соответствия регулярных выражений и команд замещения. Специальный малый язык для написания тестовых программ облегчит вам создание большого количества тестов; использование программы для написания программы для тестирования программы своеобразно увеличивает "плечо рычага", и работа облегчается в несколько раз. (В главе 9 мы еще вернемся к разговору о небольших языках и о программах, пишущих программы.) Всего у нас есть около тысячи тестов для Awk; весь их набор можно запустить одной-единственной командой, и если все прошло хорошо, то никаких сообщений не появится. Каждый раз, когда в программу добавляется новая возможность или исправляется какая-нибудь ошибка, мы добавляем новые тесты для поверки новых свойств. Каждый раз, когда программа изменяется, пусть даже совсем немного, запускается весь набор тестов — его исполнение занимает лишь пару минут. Нередко при этом выявляются совершенно неожиданные ошибки; применение такого набора не раз спасало авторов Awk от конфуза. Что же делать, если вы обнаружили ошибку? Если она не была найдена существующими тестами, создайте новый текст, нацеленный на эту конкретную проблему, и проверьте его на некорректной версии. Обнаруженная ошибка зачастую является стимулом не только для создания одного нового теста, но и вообще нового направления проверок. Кстати, не надо забывать и о том, что иногда программу можно просто снабдить механизмом защиты, который отлавливал бы ошибку. Никогда не удаляйте созданный тест. Он может помочь вам в определении того, исправлены ли уже те или иные ошибки. Ведите учет всех ошибок, изменений, исправлений — это поможет вам опознать старые проблемы и справиться с новыми. В большинстве коммерческих программистских фирм ведение подобных записей является строго обязательным. Для вас же эти записи станут способомтюхранения времени. Упражнение 6-5 Спроектируйте набор тестов для printf, используя при этом как можно больше автоматических способов. |
|
|
|