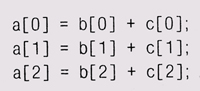|
|
|
Настройка кода Существует большое количество различных способов уменьшить время исполнения, — естественно, после того как критическое место в программе найдено. Ниже мы приводим ряд рекомендаций в этой области, однако надо всегда помнить, что применять что бы то ни было надо с осторожностью и после каждого изменения непременно выполнять возвратные тесты, чтобы быть уверенными в корректности работы кода. Помните, что хорошие компиляторы сами выполняют некоторые из описываемых усовершенствований, и вы можете только запутать программу. Что бы вы ни применяли, после каждого изменения выполняйте замеры времени. Объединяйте общие выражения. Если некоторое сложное вычисление встречается в вашем коде несколько раз, выполните его единожды и запомните результат. Например, в главе 1 мы показали вам макрос, который вычислял расстояние, дважды подряд вызывая sq rt с одинаковыми значениями; в результате вычисление выглядело так: ? sqrt(dx*dx + dy*dy) + ((sqrt(dx*dx + dy*dy) > 0) ? ... ) Вычислите корень один раз, а дальше используйте полученное значение. Если вычисление выполняется в цикле, но при этом не зависит ни от каких параметров, изменяющихся в этом цикле, вынесите его из цикла и подставляйте далее его значение: for (i = 0; i < nstarting[cj; можно заменить на n = nstarting[c] ; Заменяйте дорогостоящие операции на более дешевые. Термин понижение мощности (reduction of strength) относится к такому виду оптимизации, как замена дорогостоящей операции на более дешевую. Когда-то давно этот термин обозначал в основном замену умножения сложениями или сдвигами, правда, сейчас непосредственно на этом вы вряд ли что-то выгадаете. Однако деление и взятие остатка гораздо медленнее умножения, так что код можно несколько улучшить, заменив деление умножением на обратное значение, а взятие остатка при делителе, являющемся степенью двойки, можно заменить использованием битовой маски. Замена индексации массивов указателями в С или C++ может ускорить код, правда, большинство компиляторов выполняет это автоматически. Может быть вполне выгодной и замена вызова функции простым непосредственным вычислением. Расстояние на плоскости определяется по формуле sqrt(dx*dx+dy*dy), так что для выяснения того, какая из двух точек находится дальше, в принципе надо вычислить два квадратных корня. Но это решение можно принять и сравнивая квадраты расстояний, то есть if (dx1*dx1+dy1*dy1 < dx2*dx2+dy2*dy2) даст тот же результат, но без вычисления корней. Другой пример дают сравнения строк с текстовыми образцами, вро-| де нашего спам-фильтра или д rep. Если образец начинается с буквы, то по всему введенному тексту осуществляется быстрый поиск этой буквы, и если вхождений не обнаружено, то более сложные механизмы поиска вообще не вступают в дело. Избавьтесь от циклов или упростите их. Организация и исполнение цикла требуют некоторых временных затрат, так что, если тело цикла не слишком длинно и выполняется не слишком много раз, может оказаться более эффективным избавиться от цикла вообще и выписать все дей-| ствия последовательно. Таким образом, например, for (i =0;
Если цикл более длинный, тот же тип преобразования можно применить для уменьшения количества операций:
Обратите внимание на то, что это можно осуществить только в том случае, если длина в кратное количество раз отличается от размера шага, в противном случае надо обрабатывать дополнительный код на границах, а в таких местах очень часто возникают ошибки, заодно теряется и часть отыгранной эффективности. Кэшируйте часто используемые значения.
Кэшированные значения не надо вычислять заново. Кэширование использует
преимущества локолъ-ности (locality) — тенденции программ (да и людей)
чаще использовать те элементы, обращение к которым происходило недавно.
В вычислительном оборудовании кэши используются очень широко; оснащение
компьютера кэшем серьезно ускорило его работу. То же самое относится и
к программам. Например, web-браузеры кэшируют страницы и рисунки для того,
чтобы как можно меньше прибегать к повторному получению данных из Интернета.
Много лет назад мы писали программу просмотра текста для вывода на печать;
в этой программе специальные символы, вроде %, приходилось выбирать из
специальной таблицы. Измерения показали, что по большей части специальные
символы использовались для рисования линий (строк), состоящих из многократного
Лучше всего, если операция кэширования будет невидима снаружи, то есть не будет влиять на программу никаким образом, кроме как ускорять ее исполнение. В случае с нашим предпечатным просмотром интерфейс функции отрисовки не изменился, вызов всегда выглядел как drawchar(c); В исходной версии drawchaг осуществлялся вызов show(lookup(c)). В реализации с кэшированием для запоминания последнего вызванного символа и его кода использовались внутренние статические переменные:
Если запрашиваемые блоки примерно равны, то можно пожертвовать J местом ради выигрыша во времени и выделять сразу столько памяти, чтобы хватило на самый большой запрос. Например, для работы с короткими строками может оказаться эффективным использование одного и того же размера для всех строк, не превышающих фиксированной длины. Некоторые алгоритмы могут использовать выделение памяти, осуще- i ствляемое по принципу стека: когда выполняется сразу целая последовательность выделений памяти, а затем она освобождается вся целиком. При таком подходе аллокатор получает сразу большой блок памяти, который использует как стек, по необходимости заталкивая в него новые элементы и в конце высвобождая их все одной операцией. Некоторые библиотеки С содержат специальную функцию alloca для такого способа выделения памяти, хотя она и не входит в стандарт. В качестве источника памяти она использует локальный стек вызовов; высвобождаются элементы в тот момент, когда заканчивает работу функция, вызвавшая alloca. Буферизуйте ввод и вывод. При буферизации трансакции объединяются в блоки с тем, чтобы часто исполняемые операции выполнялись с минимально возможными затратами, а очень дорогостоящие операции выполнялись только в случае крайней необходимости. Стоимость операции, таким образом, распределяется между несколькими значениями данных. Например, когда программа на С вызывае-Aprintf, символы сохраняются в буфере, но не передаются операционной системе до тех пор, пока буфер не будет заполнен или не поступит явный запрос на его очистку. В свою очередь, операционная система может задержать запись данных на диск. Помеха в том, что данные становятся видимыми после очистки буферов вывода; и в.худшем случае — информация, содержащаяся в буфере, при аварийной остановке программы пропадает. Специальные случаи обрабатывайте отдельно. Обрабатывая объекты одинакового размера в отдельном коде, специализированные аллокато-ры уменьшают затраты места и времени и при этом уменьшают степень фрагментации памяти. В графической библиотеке для системы Inferno основная функция d raw была написана насколько возможно просто и непосредственно. После того как она заработала в таком виде, началась оптимизация различных частных случаев, выбранных в результате профилирования (по одному изменению за раз). Большим плюсом являлось то, что оптимизированную версию всегда можно было сравнить с исходной (мы уже говорили о прототипах, — это тот самый случай). В конце концов оптимизации подверглось лишь незначительное число случаев — из-за того, что динамическое распределение вызовов функции рисования очень сильно зависело собственно от вывода символов на экран; для многих случаев просто не имело смысла писать какой-то особо умный код. Используйте предварительное вычисление результатов. Иногда ускорить работу программы можно предварительно вычислив некоторые значения. Мы проделали это в спам-фильтре, вычислив заранее strlen(pat[i]) и сохранив его в массиве patlen[i ]. Если графической системе приходится постоянно вычислять математическую функцию вроде синуса, но только Для какого-то дискретного набора значений, например только для целых значений градусов, то быстрее заранее вычислить таблицу из 360 элементов (или вообще включить ее в программу в виде данных) и обращаться к этой таблице по индексу. Это типичный пример экономии времени за счет места. Существует множество способов замены кода данными или выполнения вычислений при компиляции для сохранения времени, а иногда и места. Например, функции из библиотеки ctype, вроде isdigit, почти всегда реализованы с помощью индексации в таблице битовых флагов, а не посредством вычисления последовательности тестов. Используйте приближенные значения. Если идеальная аккуратность; вычислений не нужна, лучше использовать типы данных с низкой точностью. На старых или маломощных машинах, а также на машинах, симулирующих плавающую точку программно, вычисления с плавающей точкой, выполняемые с обычной точностью, происходят быстрее, чем с двойной точностью, так что для экономии времени стоит использовать float вместо double. Подобный прием используется в некоторых совре-'; менных графических редакторах. Стандарт IEEE для плавающей точки требует "чистого выхода за пределы точности" (graceful underflow) no мере приближения вычислений к нижней границе точности значений, однако такие вычисления достаточно накладны. Для изображений подобные изыски не обязательны, гораздо быстрее отсекать малозначимые части значений; главное, при этом абсолютно ничего не теряется. Это не только экономит время при уменьшении значимости чисел, но и позво- ] ляет использовать для вычислений более простые аппаратные средства. | Использование целочисленных функций sin и cos — еще один пример использования приближенных вычислений. Перепишите код на языке более низкого уровня. Как правило, чем | ниже уровень языка, тем более быстрым оказывается код, хотя за это и приходится платить большими затратами на его написание. Так, переписав некоторый критичный фрагмент программы с C++ или Java на С или заменив интерпретируемый скрипт программой на компилируемом языке, вы, скорее всего, добьетесь сокращения времени исполнения. Порой использование машинно-ориентированного (и, стало быть, машинно-зависимого) кода может дать существенный выигрыш в быстродействии. Это скорее последняя надежда, чем часто применяемый ход, поскольку это прямо-таки уничтожает переносимость и вызывает большие трудности при дальнейшей поддержке и модернизации программы. Почти всегда операции, которые надо выражать на языке ассемблера, — это небольшие функции, которые следует объединить в библиотеку: типичными примерами являются memset и memmove или графические операции. Общий подход должен быть таким: сначала надо написать максимально понятный код на языке высокого уровня и проверить его на корректность, старательно оттестировав; мы проделывали такое для memset в главе 6. Получается переносимая версия, которая будет работать всегда и везде, хотя и довольно медленно. Теперь при переходе в новую среду вы всегда будете иметь версию, которая с гарантией работает, и работает правильно, и, написав версию на ассемблере, сравните ее с работающим прототипом. При возникновении ошибок проверять надо в первую очередь, естественно, новую версию. Вообще, полезно и удобно иметь под рукой реализацию для сравнения. Упражнение 7-4 Один из способов ускорить функцию типа memset — переписать ее так, чтобы она записывала данные порциями в слово, а не в байт; такая версия почти наверняка будет ближе к аппаратнымт1редставлениям, и затраты на цикл снизятся в четыре или восемь раз. Отрицательной стороной является то, что при этом возникает большое количество вариантов окончаний блоков, если объект приложения функции не выровнен по границе слова (или не кратен слову). Напишите версию memset, выполняющую подобную оптимизацию. Сравните ее производительность с существующей библиотечной версией и с простейшим вариантом побайтового цикла. Упражнение 7-5 Напишите функцию выделения памяти smalloc для строк С, которая бы использовала специальный аллокатор для коротких строк, но вызывала непосредственно malloc для больших. Для представления тех и других строк вам придется определить структуру struct. Как вы определите, где переходить от вызова smalloc к malloc? |
|
|
|