|
|
|
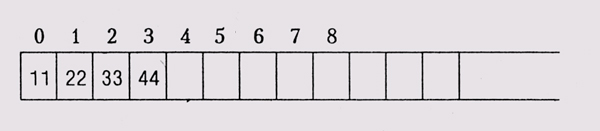
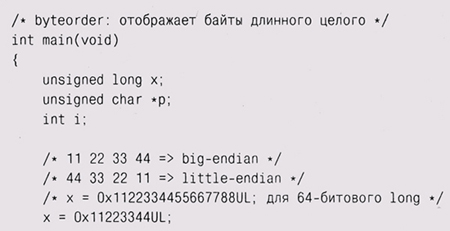
Порядок байтов Несмотря на все описанные выше недостатки, иногда двоичные данные оказываются необходимы. Например, они несравненно более компактны и их гораздо быстрее декодировать, а эти факторы очень важны для компьютерных сетей. Но двоичные данные имеют серьезнейшие] проблемы с переносимостью. По крайней мере один вопрос решен: все современные машины имеют! 8-битовые байты. Однако все объекты, большие байта, представляются на разных машинах по-разному, поэтому полагаться на какие-то определенные свойства было бы ошибкой. Короткие целые числа (обычно] 16 битов, или 2 байта) могут иметь младший байт, расположенный как по меньшему адресу (little-endian, младшеконечное расположение), чем I старший, так и по большему (big-endian, старшеконечное)1. Выбор варианта произволен, а некоторые машины вообще поддерживают обе! модели. Итак, несмотря на то, что и старшеконечные и младшеконечные машины рассматривают память как последовательность слов, расположен-! ных в одном и том же порядке, байты внутри слова они интерпретируют! различно. На приведенной диаграмме четыре байта, начинающиеся с поя зиции 0, представляют шестнадцатеричное целое 0x11223344 для старшеконечников и 0x44332211 —для младшеконечников.
Для того чтобы увидеть порядок байтов в действии, запустите следующую программу:
11 22 33 44 на младшеконечнике — 44 33 22 11 а на PDP-11 (16-битовая машина, все еще встречающаяся во встроенных системах) результатом будет 22 11 44 33 На машинах с 64-битовым типом long мы можем рассмотреть константу большей длины и увидеть те же результаты. Наша программа выглядит довольно глупо, но если нам надо послать целое число через побайтовый интерфейс, например по сети, то надо решить, какой байт посылать первым, а какой вторым, и в этом выборе суть проблемы со старше- и младшеконечниками. Другими словами, наша программа неявнр выполняет то, что выражение fwrite(&x, sizeof(x), 1, stdout); делает явным образом. Небезопасно писать (отправлять) int (или short, или long) на одном компьютере и читать это число как int на другом. Например, если компьютер-передатчик пишет с помощью unsigned short x; а компьютер-приемник производит чтение так: unsigned short x; то, если эти компьютеры имеют разный порядок байтов, значение х будет воспроизведено неправильно. Например, если отправлено было число 0x1000, то прочитано оно будет как 0x0010. Эта проблема часто решается посредством условной компиляции и перестановки байтов, то есть примерно так:
Если ситуация выглядит невесело для short, то для более длинных типов она еще хуже — для них существует больше способов перепутать байты. А если к этому добавить еще всяческие преобразования между членами структур, ограничения на выравнивание и абсолютно таинственный порядок байтов в старых машинах, то проблема покажется 4 просто неразрешимой. Используйте при обмене данными фиксированный
порядок байтов.
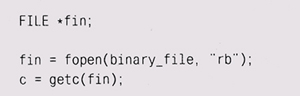
Побайтовая обработка может показаться довольно дорогим удовольствием, но в сравнении с вводом-выводом, при котором необходима упаковка и распаковка данных, потери времени окажутся незначительными. Представьте себе систему X Window, в которой клиент пишет данные с тем порядком байтов, что используется у него на машине, а сервер должен распаковывать все, что клиент посылает. На клиентском конце достигнута экономия в несколько инструкций, но сервер становится больше и сложнее, поскольку ему приходится обрабатывать одновременно данные с разными порядками байтов: ведь клиенты вполне могут иметь различные типы машин. В общем, сложностей куда больше. Кроме того, не забывайте, что это графическая оболочка, где расходы на распаковку байтов будут с лихвой перекрыты выполнением той графической операции, которую они содержат. Система X Window воспринимает данные от клиента с любым порядком байтов: считается, что это забота сервера. А система Plan 9, наоборот, сама задает порядок байтов для отправки сообщений файл-серверу (или графическому серверу), а данные запаковываются и распаковываются неким универсальным кодом вроде приведенного выше. На практике определить временные затраты во время исполнения оказывается практически невозможно; можно только сказать, что на фоне ввода-вывода упаковка данных оказывается малозаметной. Java — язык более высокого уровня, чем С и C++, в нем порядок байтов скрыт совсем. Библиотеки представляют интерфейс Serializable, который определяет, как элементы данных пакуются для передачи. Однако, если вы пишете на С или C++, всю работу придется выполнять самостоятельно. Главное, что можно сказать про побайтовую обработку: она решает имеющуюся проблему для всех машин с 8-битовыми байтами, причем решает без участия flifdef. Мы еще вернемся к этой теме в следующей главе. Итак, лучшим решением нередко оказывается преобразование информации в текстовый формат, который (не считая проблемы CRLF) является абсолютно переносимым: не существует никаких неопределенностей с его представлением. Однако и текстовый формат не является панацеей. Время и размер для некоторых программ могут быть критичны, кроме того, часть данных, особенно числа с плавающей точкой, могут потерять точность при округлениях в процессе передачи через printf и scanf. Если вам надо передавать числа с плавающей точкой, особо заботясь о точности, убедитесь, что у вас есть хорошая библиотека форматированного ввода-вывода; такие библиотеки существуют, просто ее может не оказаться конкретно в вашей системе. Особенно сложно представлять числа с плавающей точкой для переноса их в двоичном формате, но при должном внимании текст может эту проблему решить. Существует один тонкий момент, связанный с использованием стан-| дартных функций для обработки двоичных файлов, — эти файлы необходимо открывать в двоичном режиме:
|
|
|
|