|
|
|
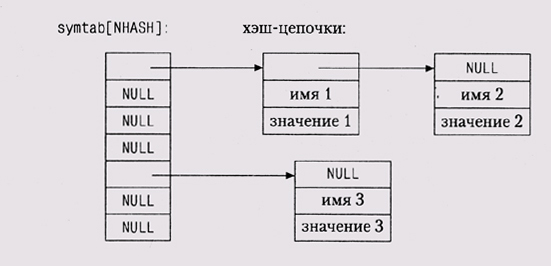
2.9. Хэш-таблицы Хэш-таблицы (hash tables) — одно из величайших изобретений информатики. Сочетание массивов и списков с небольшой добавкой математики позволило создать эффективную структуру для хранения и* получения динамических данных. Типичное применение хэш-таблиц -символьная таблица, которая ассоциирует некоторое значение (данные) с каждым членом динамического набора строк (ключей). Ваш любимый компилятор практически наверняка использует хэш-таблицу для управления информацией о переменных в вашей программе. Ваш web-браузер наверняка использует хэш-таблицу для хранения адресов страниц, которые вы недавно посещали, а при соединении вашего компьютера с Интернетом, вероятно, она применяется для оперативного хранения (cache — кэширования) недавно использованных доменных имен и их IP-адресов. Идея состоит в том, чтобы пропустить ключ через хэш-функцию (hash function) для получения хэш-значения (hash value), которое было бы равномерно распределено по диапазону целых чисел приемлемого размера. Это хэш-значение используется как индекс в таблице, где хранится информация. Java предоставляет стандартный интерфейс к хэш-таб-лицам. В С и C++ обычно с каждым хэш-значением (или "bucket" -"корзиной") ассоциируется список элементов, которые обладают этим значением, как показано на следующем рисунке:
Поскольку хэш-таблица — массив списков, то тип элементов для нее такой же, как и для списка:
if (lookup("name") == NULL)
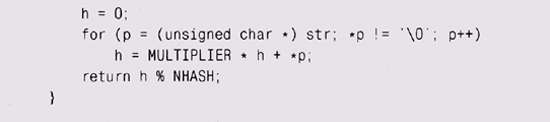
то хэш-функция вычисляется дважды. Насколько большим должен быть массив? Основная идея заключается в том, что он должен быть достаточно большим, чтобы любая хэш-цепочка была бы длиной всего в несколько элементов и поиск занимал время О(1). Например, у компилятора размер массива должен быть порядка нескольких тысяч, так как в большом исходном файле — несколько тысяч строчек и вряд ли различных идентификаторов имеется больше, чем по одному на строчку кода. Теперь нам нужно решить, что же наша хэш-функция, hash, будет вычислять. Она должна быть детерминированной, достаточно быстрой и распределять данные по массиву равномерно. Один из наиболее распространенных алгоритмов хэширования для строк получает хэш-значение, добавляя каждый байт строки к произведению предыдущего значения на некий фиксированный множитель (хэш). Умножение распределяет биты из нового байта по всему до сих пор не считанному значению, так что в конце цикла мы получим хорошую смесь входных байтов. Эмпирически установлено, что значения 31 и 37 являются хорошими множителями в хэш-функции для строк ASCII.
Хэш-функция возвращает результат по модулю размера массива. Если хэш-функция распределяет данные равномерно, то точный размер массива неважен. Трудно, однако, гарантировать, что хэш-функция независима от размера массива, и даже у хорошей функции могут быть проблемы с некоторыми наборами входных данных. Поэтому имеет смысл сделать размер массива простым числом, чтобы слегка подстраховаться, обеспечив отсутствие общих делителей у размера массива, хэш-мультипликатора и, возможно, значений данных. Эксперименты показывают, что для большого числа разных строк трудно придумать хэш-функцию, которая работала бы гораздо лучше, чем эта, зато легко придумать такую, которая работает хуже. В ранних версиях Java была хэш-функция для строк, работавшая более эффективно, если строка была длинной. Хэш-функция работала быстрее, анализируя только 8 или 9 символов через равные интервалы в строках длиннее, чем 16 символов, начиная с первого символа. К сожалению, хотя хэш-функция работала быстрее, у нее были очень плохие статистические показатели, что сводило на нет выигрыш в производительности. Пропуская части строки, она нередко выкидывала именно различающиеся части строк. Имена файлов начинаются с длинных идентичных префиксов — имен каталогов — и могут отличаться только несколькими последними символами (например, .Java и .class). Адреса в Internet обычно начинаются с http://www. и заканчиваются на . html, поэтому все различия у них в середине. Хэш-функция частенько проходила только по неразличающейся части в имени, в результате чего образовывались более длинные хэш-цепочки, что замедляло поиск. Проблема была решена заменой хэш-функции на эквивалентную той, что мы привели выше (с мультипликатором 37), которая исследует каждый символ в строке. Хэш-функция, которая неплохо подходит для одного набора данных (например, имен переменных), может плохо подходить для другого (адреса Internet), так что потенциальная хэш-функция должна быть протестирована на разных наборах типичных входных данных. Хорошо ли она перемешивает короткие строки? Длинные строки? Строки одинаковой длины с небольшими изменениями? Хэшировать можно не только строки. Можно "смешать" три координаты частицы при физическом моделировании, тем самым уменьшив размер хранилища до линейной таблицы (0(количество точек)) вместо трехмерного массива (0(размер_по_х хразмер_nojj X размер_no_z)). Один примечательный случай использования хэширования — программа Джерарда Холзманна (Gerard Holzmann) для анализа протоколов и параллельных систем Supertrace. Supertrace берет полную информацию о каждом возможном состоянии наблюдаемой системы и хэширует эту информацию для получения адреса единственного бита в памяти. Если этот бит установлен, то данное состояние наблюдалось и раньше; если нет, то не наблюдалось. В Supertrace используется хэш-таблица длиной во много мегабайт, однако в каждой ячейке хранится только один бит. Цепочки не строятся; если два разных состояния совпали по своей хэш-функции, то программа этого не заметит. Supertrace рассчитана на то, что вероятность коллизии мала (она не обязана быть нулем, поскольку Supertrace использует вероятностные, а не детерминированные вычисления). Поэтому хэш-функция здесь очень аккуратна; она использует циклический избыточный код (cyclic redundancy check — CRC) — функцию, которая тщательно перемешивает данные. Хэш-таблицы незаменимы для символьных таблиц, поскольку они предоставляют (почти всегда) доступ к каждому элементу за константное время. У них есть свои ограничения. Если хэш-функция плоха или размер массива слишком мал, то списки могут стать достаточно длинными. Поскольку списки не отсортированы, это приведет к линейному доступу (0(и)). Элементы нельзя напрямую получить в отсортированном виде, однако их легко подсчитать, выделить память под массив, заполнить его указателями на элементы и отсортировать их. Что и говорить, константное время операций поиска, вставка и удаление — это такое свойство хэш-таблицы, которого не достичь никакими другими технологиями. Упражнение 2-14 Наша хэш-функция замечательна для повседневного хэширования строк. Однако на нарочно придуманных данных она может работать плохо. Сконструируйте набор данных, приводящий к плохому поведению нашей хэш-функции. Проще ли найти плохой набор для других значений NHASH? Упражнение 2-15 Напишите функцию для доступа к последовательным элементам хэш-таблицы в несортированном порядке. Упражнение 2-16 Измените функцию lookup так, что если средняя длина списка превысит некое значение х, то массив автоматически расширяется в у раз и хэш-таблица перестраивается. Упражнение 2-17 Спроектируйте кэш-функцию для хранения координат точек в двумерном пространстве. Насколько легко ваша функция адаптируется к изменениям в типе координат, например при переходе от целого типа данных к значениям с плавающей точкой, или при переходе от декартовой к полярной системе координат, или при увеличении количества измерений?
|
|
|
|