|
|
|
| Деревья Дерево — иерархическая структура данных, хранящая набор элементов. Каждый элемент имеет значение и может указывать на ноль или более других элементов. На каждый элемент указывает только один другой элемент. Единственным исключением является корень дерева, на который не указывает ни один элемент. Входящие в дерево элементы называются его вершинами. Есть много типов деревьев, которые отражают сложные структуры, например деревья синтаксического разбора (parse trees), хранящие синтаксис предложения или программы, либо генеалогические деревья, описывающие родственные связи. Мы продемонстрируем основные принципы на деревьях двоичного поиска, в которых каждая вершина (node) имеет по две связи. Они наиболее просто реализуются и демонстрируют наиболее важные свойства деревьев. Вершина в двоичном дереве имеет значение и два указателя, left и right, которые показывают на его дочерние вершины. Эти указатели могут быть равны null, если у вершины меньше двух дочерних вершин. Структуру двоичного дерева поиска определяют значения в его вершинах: все дочерние вершины, расположенные левее данной, имеют меньшие значения, а все дочерние вершины правее — большие. Благодаря этому свойству мы можем использовать разновидность двоичного поиска для быстрого поиска значения по дереву или определения, что такого значения нет. Вариант структуры Nameval для дерева пишется сразу:
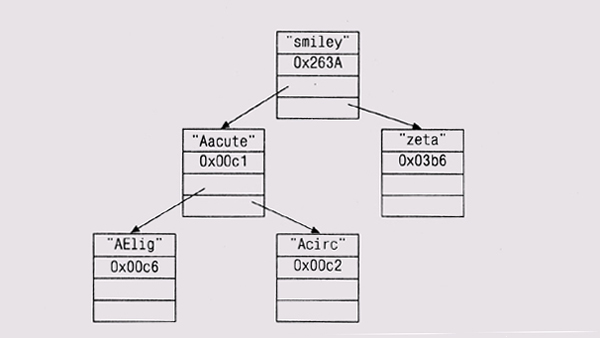
В качестве конкретного примера на приведенном рисунке показано подмножество таблицы символов в виде дерева двоичного поиска для структур Nameval, отсортированных по ASCII-значениям имен символов.
Дерево двоичного поиска (которое в данном параграфе мы будем называть просто "деревом") достраивается рекурсивным спуском по дереву; на каждом шаге спуска выбирается соответствующая правая или левая ветка, пока не найдется место для вставки новой вершины, которая должна быть корректно инициализированной структурой типа Nameval: имя, значение и два нулевых указателя. Новая вершина добавляется как лист дерева, то есть у него пока отсутствуют дочерние вершины.
Процедура weprintf — это вариант eprintf; она печатает сообщение, начинающееся
со слова warning (предупреждение), но, в отличие от eprintf, работу программы
не завершает. Если элементы вставляются в дерево в том же порядке, в каком они появляются, то дерево может оказаться несбалансированным или даже весьма плохо сбалансированным. Например, если элементы приходят уже в отсортированном виде, то код каждый раз будет спускаться на еще одну ветку дерева, создавая в результате список из правых ссылок, со всеми "прелестями" производительности списка. Если же элементы поступают в произвольном порядке, то описанная ситуация вряд ли произойдет и дерево будет более или менее сбалансированным. Трудно реализовать деревья, которые гарантированно сбалансированы; это одна из причин существования большого числа различных видов деревьев. Мы просто обойдем данный вопрос стороной и будем считать, что входные данные достаточно случайны, чтобы дерево было достаточно сбалансированным. Код для функции поиска похож на функцию insert:
Во-вторых, эти процедуры рекурсивны. Если их переписать итеративно, то они будут похожи на двоичный поиск еще больше. На самом деле итеративная версия функции lookup может быть создана в результате элегантной трансформации рекурсивной версии. Если мы еще не нашли элемента, то последнее действие функции заключается в возврате результата, получающегося при вызове себя самой, такая ситуация называется хвостовой рекурсией (tail recursion). Эта конструкция может быть преобразована в итеративную форму, если подправить аргументы и стартовать функцию заново. Наиболее прямой метод — использовать оператор перехода goto, но цикл while выглядит чище:
Иногда структура дерева отражает какое-то внутреннее упорядочение данных, как в генеалогических деревьях, и порядок обхода листьев будет зависеть от отношений, которые дерево представляет. Фланговый порядок (in-order) обхода выполняет операцию в данной вершине после просмотра ее левого поддерева и перед просмотром правого:
applyinorder(treep, printnv, "%s: %x\n"); Сразу намечается вариант сортировки: вставляем элементы в дерево, выделяем память под массив соответствующего размера, а затем используем фланговый обход для последовательного размещения их в массиве. Восходящий порядок (post-order) обхода вызывает операцию для данной вершины после просмотра вершин-детей:
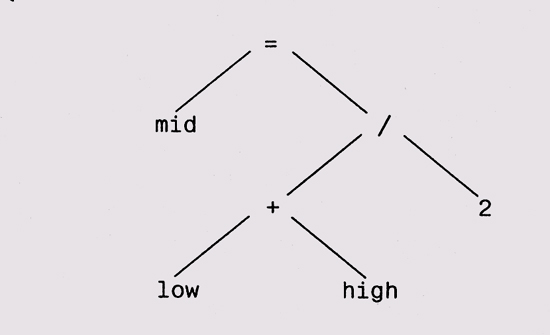
Нисходящий порядок (pre-order) используется редко, так что мы не будем его рассматривать. На самом деле деревья двоичного поиска применяются редко, хотя В-деревья, обычно сильно разветвленные, используются для хранения информации на внешних носителях. В каждодневном программировании деревья часто используются для представления структур действий и выражений. Например, действие mid = (low + high) / 2; может быть представлено в виде дерева синтаксического разбора (parse tree), показанного на рисунке ниже. Для вычисления значения дерева нужно обойти его в восходящем порядке и выполнить в каждой вершине соответствующее действие.
Упражнение 2-11 Сравните быстродействие lookup и nrlookup. Насколько рекурсия медленнее итеративной версии? Упражнение 2-12 Используйте фланговый обход для создания процедуры сортировки. Какова ее временная сложность? При каких условиях она может работать медленно? Как ее производительность соотносится с нашей процедурой quicksort и с библиотечной версией? Упражнение 2-13 Придумайте и реализуйте набор тестов, удостоверяющих, что процедуры работы с деревьями корректны. |
|
|
|