|
|
|
Динамически расширяемые массивы Массивы, использованные в нескольких предыдущих разделах, были статическими,
их размер и содержимое задавались во время компиляции. Если потребовать,
чтобы некоторую таблицу слов или символов HTML можно было изменять во
время выполнения, то хэш-таблица была бы для этой цели более подходящей
структурой. Вставка в отсортированный массив п элементов по одному занимает
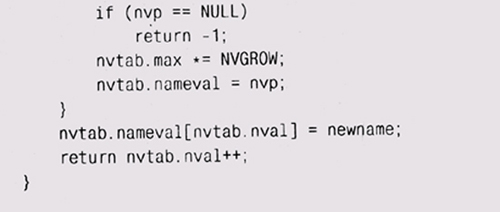
О(n2), чего стоит избегать при больших n. Следующий код определяет расширяемый массив с элементами типа Nameval: новые элементы добавляются в хвост массива, который удлиняется при необходимости. Доступ к каждому элементу по его индексу происходит за константное время. Эта конструкция аналогична векторным классам из библиотек C++ и Java.
Вызов reallос увеличивает массив до новых размеров, сохраняя существующие элементы, и возвращает указатель на него или NULL при недостатке памяти. Удвоение размера массива при каждом вызове realloc сохраняет средние "ожидаемые" затраты на копирование элемента постоянными; если бы массив увеличивался каждый раз только на один элемент, то производительность была бы порядка 0(п2). Поскольку при перераспределении памяти адрес массива может измениться, то программа должна обращаться к элементам массива по индексам, а не через указатели. Заметьте, что код не таков: ? nvtab.nameval = (Nameval *) realloc(nvtab.nameval, потому что при такой форме если вызов realloc не сработает, то исход-ный-массив будет утерян. Мы задаем очень маленький начальный размер массива (NVINIT = 1). Это заставляет программу увеличивать массив почти сразу, что гарантирует проверку данной части программы. Начальное значение может быть и увеличено, когда программа начнет реально использоваться, однако затраты на стартовое расширение массива ничтожны. Значение, возвращаемое realloc, не обязательно должно приводиться к его настоящему типу, поскольку в С нетипизированные указатели (void *) приводятся к любому типу указателя автоматически. Однако в C++ это не так; здесь преобразование обязательно. Можно поспорить, что безопаснее: преобразовывать типы (это честнее и понятнее) или не преобразовывать (поскольку в преобразовании легко может закрасться ошибка). Мы выбрали преобразование, потому что тогда программа корректна как в С, так и в C++. Цена такого решения — уменьшение количества проверок на ошибки компилятором С, но это неважно, когда мы производим дополнительные проверки с помощью двух компиляторов. Удаление элемента может быть более сложной операцией, поскольку нам нужно решить, что же делать с образовавшейся "дыркой" в массиве. Если порядок элементов не имеет значения, то проще всего переставить последний элемент на место удаленного. Однако, если порядок должен быть сохранен, нам нужно сдвинуть элементы после "дырки" на одну позицию:
определены две функции: memcpy, которая работает быстрее, но может затереть память, если источник и приемник данных пересекаются, и memmove, которая может работать медленнее, но зато всегда корректна. Бремя выбора между скоростью и корректностью не должно взваливаться на программиста; должна была бы быть только одна функция. Считайте, что это так и есть, и всегда используйте memmove. Мы могли бы заменить вызов memmove следующим циклом:
Альтернатива перемещению элементов — помечать удаленные элементы как неиспользуемые. Тогда для добавления элемента нам надо сначала найти неиспользуемую ячейку и увеличивать массив, только если свободного места не найдено. В данном примере элемент можно пометить как неиспользуемый, установив значения поля name в NULL. Массивы — простейший способ группировки данных; вовсе не случайно большинство языков имеют эффективные и удобные индексируемые массивы и даже представляют строки в виде массивов символов. Массивы просты в использовании, обладают константным доступом к любому элементу, хорошо работают с двоичным поиском и быстрой сортировкой, а также почти совсем не тратят лишних ресурсов. Для наборов данных фиксированного размера, которые могут быть созданы даже во время компиляции, или же для гарантированно небольших объемов данных массивы подходят идеально. Однако хранение меняющегося набора значений в массиве может быть весьма ресурсоемким, поэтому, если количество элементов непредсказуемо и потенциально неограниченно, может оказаться удобнее использовать другую структуру данных. Упражнение 2-5 В приведенном выше коде функция delname не вызывает realloc для возврата системе памяти, освобожденной удалением элемента. Имеет ли смысл это делать? Как решить, стоит это делать или нет? Упражнение 2-6 Внесите необходимые изменения в функции delname и addname, чтобы удаленные элементы помечались как неиспользуемые. Насколько остальная программа не зависит от этого изменения? |
|
|
|