|
|
|
|
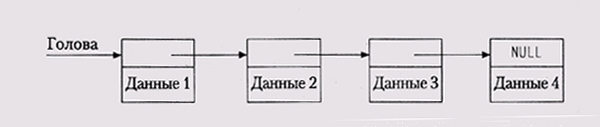
Списки По своей встречаемости в типичных программах списки занимают второе место после массивов. Многие языки имеют встроенные типы списков, некоторые, такие как Lisp, даже построены на них, но в языке С мы должны конструировать их самостоятельно. В C++ и Java работа со списками поддерживается стандартными библиотеками, но и в этом случае нужно знать их возможности и типичные применения. В данном параграфе мы собираемся обсудить использование списков в С, но уроки из этогр обсуждения можно извлечь и для более широкого применения. Простым цепным списком (single-linked list) называется последовательность элементов, каждый из которых содержит данные и указатель на следующий элемент. Головой списка является указатель на первый элемент, а конец помечен нулевым указателем. Ниже показан список из четырех элементов:
Эти различия подсказывают, что если набор данных будет часто меняться, особенно при непредсказуемом количестве элементов, то нужно использовать список; напротив, массив больше подходит для относительно статичных данных. Фундаментальных операций со списком совсем немного: добавить элемент в начало или конец списка, найти указанный элемент, добавить новый элемент до или после указанного элемента и, возможно, удалить элемент. Простота списков позволяет при необходимости легко добавлять новые операции. Вместо того чтобы определить специальный тип List, обычно в С начинают определение списка с описания типа для элементов, вроде нашего Nameval, и добавляют в него указатель на следующий элемент:
Простейший и самый быстрый способ собрать список — это добавлять новые элементы в его начало:
nvlist = addf ront(nvlist, newitem( "smiley", Ox263A)); Добавление элемента в конец списка — процедура порядка 0(п), поскольку нам нужно пройтись по всему списку до конца:
Для поиска элемента с заданным именем нужно пройтись по указателям next:
* void (*fn)(Nameval*, void*) определяет f n как указатель на функцию с возвращаемым значением типа void, то есть как переменную, содержащую адрес функции, которая возвращает void. Функция имеет два параметра — типа Nameval * (элемент списка) и void * (обобщенный указатель на аргумент для этой функции). Для использования apply, например для вывода элементов списка, мы можем написать тривиальную функцию, параметр которой будет восприниматься как строка форматирования:
apply(nvlist, printnv, "%s: %x\n"); Для подсчета количества элементов мы определяем функцию, параметром которой будет указатель на увеличиваемый счетчик:
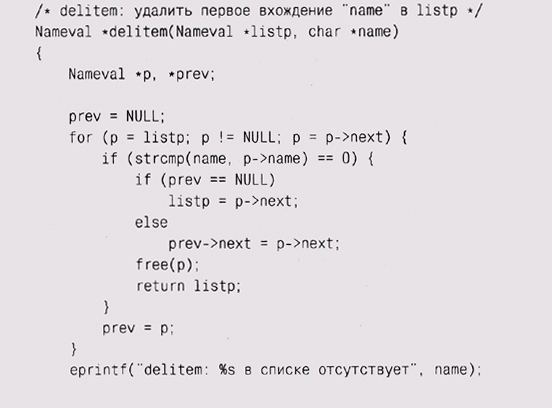
? for ( ; listp != NULL; listp = listp->next) ? то значение listp->next могло быть затерто вызовом free и код бы не работал. Заметьте, что функция freeall не освобождает память, выделенную под строку listp->name. Это подразумевает, что поле name каждого элемента типа Nameval было освобождено где-то еще либо память под него не была выделена. Чтобы обеспечить корректное выделение памяти под элементы и ее освобождение, нужно согласование работы newitem и f гее-all; это некий компромисс между гарантиями того, что память будет освобождена, и того, что ничего лишнего освобождено не будет. Именно здесь при неграмотной реализации часто возникают ошибки. В других языках, включая Java, данную проблему за вас решает сборка мусора. К теме управления ресурсами мы еще вернемся в главе 4. Удаление одного элемента из списка — более сложный процесс, чем добавление:
Функция eprintf выводит сообщение об ошибке и завершает программу, что в лучшем случае неуклюже. Грамотное восстановление после произошедших ошибок может быть весьма трудным и требует долгого обсуждения, которое мы отложим до главы 4, где покажем также реализацию eprintf. Представленные основные списочные структуры и операции применимы в подавляющем большинстве случаев, которые могут встретиться в ваших программах. Однако есть много альтернатив. Некоторые библиотеки, включая библиотеку стандартных шаблонов (Standard Template Library, STL) в C++, поддерживают двухсвязные списки (double-linked lists: списки с двойными связями), в которых у каждого элемента есть два указателя: один — на последующий, а другой — на предыдущий элемент. Двухсвязные списки требуют больше ресурсов, но поиск последнего элемента и удаление текущего — операции порядка О( 1). Иногда память под указатели списка выделяют отдельно от данных, которые они связывают; такие списки несколько труднее использовать, но зато одни и те же элементы могут встречаться более чем в одном списке одновременно. Кроме того, что списки годятся для ситуации, когда происходят удаления и вставки элементов в середине, они также хороши для управления данными меняющегося размера, особенно когда доступ к ним происходит по принципу стека: последним вошел, первым вышел (last in, first out — LIFO). Они используют память эффективнее, чем массивы, при наличии нескольких стеков, которые независимо друг от друга растут и уменьшаются. Они также хороши в случае, когда информация внутренне связана в цепочку неизвестного заранее размера, например как последовательность слов в документе. Однако если вам нужны как частые обновления, так и случайный доступ к данным, то разумнее будет использовать не такую непреклонно линейную структуру данных, а что-нибудь вроде дерева или хэш-таблицы. Упражнение 2-7 Реализуйте некоторые другие операции над списком: копирование, слияние, разделение списка, вставку до или после указанного элемента. Как эти две операции вставки отличаются по сложности? Много ли вы можете использовать из того, что мы написали, и много ли вам надо написать самому? Упражнение 2-8 Напишите рекурсивную и итеративную версии процедуры reverse, переворачивающей список. Не создавайте новых элементов списка; используйте старые. Упражнение 2-9 Напишите обобщенный тип List для языка С. Простейший способ — в каждом элементе списка хранить указатель void *, который ссылается на данные. Сделайте то же для C++, используя шаблон (template), и для Java, определив класс, содержащий списки типа Obj ect. Каковы сильные и слабые стороны этих языков с точки зрения данной задачи? Упражнение 2-10 Придумайте и реализуйте набор тестов для проверки того, что написанные вами процедуры работы со списками корректны. Стратегии тестирования подробнее обсуждаются в главе 6. |
|
|
|