|
|
|
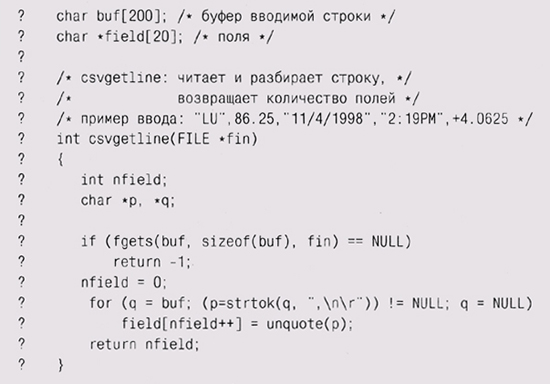
Прототип библиотеки Вряд ли нам удастся получить удачный проект библиотеки интерфейса с первой попытки. Как написал однажды Фред Брукс (Fred Brooks), "заранее планируйте выкинуть первую версию — все равно придется". Брукс писал о больших системах, но суть остается той же и для любой нормальной программы. Как правило, до тех пор пока вы не создали первой версии и не поработали с ней, трудно представить себе все аспекты работы программы настолько хорошо, чтобы спроектировать достойный продукт. Исходя из этих соображений, мы начнем создавать библиотеку CSV с версии "на выброс", с прототипа. В первой версии мы проигнорируем многие проблемы, которые должны быть решены в грамотной библиотеке, однако она будет достаточно полной, чтобы ее можно было использовать, и с помощью этой версии мы поближе познакомимся с задачей. Начнем с функции csvgetline, которая считывает одну строку данных CSV из файла в буфер, разделяет ее на поля массива, удаляет кавычки и возвращает количество полей. В течение многих лет мы уже не раз писали что-то подобное на различных языках, так что задание нам знакомо. Вот версия-прототип на С; мы пометили код вопросами, потому что это всего-навсего прототип:
Формат CSV слишком сложен, чтобы разбирать его с помощью scanf, поэтому мы использовали функцию strtok из стандартной библиотеки С. Каждый вызов strtok(p, s) возвращает указатель на первую лексему (token) из строки р, состоящую из символов, не входящих в s; st rtok обрывает эту лексему, заменяя следующий символ исходной строки нулевым байтом. При первом вызове strtok первым аргументом является сканируемая строка; при следующих вызовах для обозначения того, что сканирование должно продолжиться с той точки, где закончился предыдущий вызов, в этом месте стоит NULL. Интерфейс получился убогим. Поскольку между вызовами strtok хранит переменную в некоем неизвестном месте, в каждый момент может исполняться только одна последовательность вызовов; несвязанные перемежающиеся вызовы будут конкурировать и мешать друг другу. Использованная нами функция unquote удаляет открывающие и закрывающие кавычки, которые могут содержаться во вводимой строке. Она не обрабатывает, однако, вложенных кавычек, поэтому для прототипа ее еще можно использовать, но в общем случае она непригодна:
Мы можем прогнать через этот тест результаты работы getquotes. tcl:
Итак, у нас'есть прототип, который, кажется, в состоянии работать с данными вроде приведенных выше. Однако теперь было бы логично опробовать его на чем-то еще (особенно если мы планируем распространять эту библиотеку). Мы нашли еще один Web-сайт, позволяющий скачать биржевые котировки и получить файл с той же, собственно, информацией, но представленной в несколько иной форме: для разделения записей вместо символа йеревода строки используется символ возврата каретки (\г), а в конце файла завершающего возврата каретки нет. Выглядят новые данные так (мы отформатировали их, чтобы они умещались на странице):
При таком вводе наш прототип позорно провалился. Мы спроектировали наш прототип, изучив только один источник данных, тестирование провели на данных из того же источника. Стало быть, нечего удивляться тому, что первое же столкновение с данными из другого источника привело к гибельным последствиям. Длинные строки на вводе, большое количество полей, непредусмотренные или пропущенные разделители — все это вызывает проблемы. Наш ненадежный прототип подходит только для индивидуального использования или в целях демонстрации принципиальной пригодности выбранного подхода, но не более того. Что ж, пришло время переработать проект. При создании прототипа мы сделали ряд предположений — явных и неявных. Ниже перечислены некоторые из наших решений, зачастую не самых подходящих для универсальной библиотеки. Каждое поднимает вопрос, требующий более тщательной проработки.
В этом длинном, но далеко не полном списке приведены те решения, которые мы приняли на этапе проектирования, — и каждое решение навсегда вплетено в код. Это приемлемо для временной версии, разбирающей файлы известного формата, поступающие из одного конкретного источника. Но что будет, если формат изменится, или запятая появится внутри кавычек, или сервер выдаст длинную строку или много полей? Может показаться, что со всем этим нетрудно справиться, ведь "библиотека" мала и, в конце концов, является всего лишь прототипом. Представьте, однако, что этот код, пролежав в забвении месяцы или годы, в какой-то момент станет частью большой программы, спецификации которой будут/ меняться. Как адаптируется csvgetline? Если программу будут использовать другие люди, то скороспелые решения в ее проектировании могут вызвать проблемы, которые проявятся через долгое время. К сожалению, история многих интерфейсов подтверждает это заявление: большое количество временного, чернового кода просачивается в большие программные системы, в которых этот код так и остается "грязным" и зачастую слишком медленным. |
|
|
|