|
|
|
Библиотека для распространения Теперь с учетом того, чему мы научились на опыте прототипа, попробуем создать библиотеку общего назначения. Наиболее очевидные требования такие: csvgetline должна быть более устойчива, то есть уметь обрабатывать и длинные строки, и большое количество полей; более осторожно надо подойти и к синтаксическому разбору полей. Для создания интерфейса, который могли бы использовать и другие люди, мы должны выработать решения по аспектам, перечисленным в начале главы: интерфейсы, сокрытие деталей, управление ресурсами и обработка ошибок; их взаимосвязь оказывает сильнейшее влияние на проект. Наше разделение этих проблем было несколько произвольно, так как они сильно взаимосвязаны. Интерфейс. Мы выработали решение о трех базовых операциях: char *csvgetline(FILE *): читает новую CSV строку;
Мы будем удалять символ перевода строки из конца строки, возвращаемой csvgetline, так как, если понадобится, его можно без труда вписать обратно. С определением поля дело обстоит довольно сложно; мы попробовали собрать воедино варианты, которые встречались в электронных таблицах и других программах. Получилось примерно следующее. Поле является последовательностью из нуля или более символов. Поля разделены запятыми. Открывающие и завершающие пробелы (пропуски) сохраняются. Поле может быть заключено в двойные кавычки, в этом случае оно может содержать запятые. Поля, заключенные в двойные кавычки, могут содержать символы двойных кавычек, представляемые парой последовательных двойных кавычек, — то есть CSV поле "х""у" определяет строку х"у. Поля могут быть пустыми; поле, определяемое как "", считается пустым и эквивалентно полю, определяемому двумя смежными запятыми. Поля нумеруются с нуля. Как быть, если пользователь запросит несуществующее поле, вызвав csvfield(-l) или csvfield( 100000)? Мы могли бы возвращать "" (пустую строку), поскольку это значение можно выводить или сравнивать; программам, которые работают с различным количеством полей, не пришлось бы принимать специальных предосторожностей на случай обращения к несуществующему полю. Однако этот способ не предоставляет возможности отличить пустое поле от несуществующего. Второй вариант — выводить сообщение об ошибке или даже прерывать работу; несколько позже мы объясним, почему так делать нежелательно. Мы решили возвращать NULL — общепринятое в С значение для несуществующей строки. Сокрытие деталей. Библиотека не будет накладывать никаких ограничений ни на длину вводимой строки, ни на количество полей. Чтобы осуществить это, либо вызывающая сторона должна предоставить память, либо вызываемая сторона (то есть библиотека) должна ее зарезервировать. Посмотрим, как это организовано в сходных библиотеках: при вызове функции f gets ей передается массив и максимальный размер; если строка оказывается больше буфера, она разбивается на части. Для работы с CSV такое поведение абсолютно неприемлемо, поэтому наша библиотека будет сама выделять память по мере необходимости. Только функция csvgetline занимается управлением памятью; вне ее ничего о методах организации памяти не известно. Лучше всего осуществлять такую изоляцию через интерфейс функции: получается (то есть видно снаружи), что csvgetline читает следующую строку — вне зависимости от ее размера, csvfield(n) возвращает указатель на байты п-го поля текущей строки, a csvnf ields возвращает количество полей в текущей строке. Мы должны будем наращивать память по мере появления длинных строк или большого количества полей. Детали того, как это происходит, спрятаны в функциях csv; никакие другие части программы не знают, как это делается: использует ли библиотека маленькие массивы, наращивая их при необходимости, или, наоборот, очень большие массивы, или вообще какой-то совершенно другой подход. Точно так же интерфейс не раскрывает и того, когда же память высвобождается. Если пользователь вызывает только csvgetline, то нет надобности разделять строку на поля; это можно сделать по специальному требованию. Происходит ли разделение полей ретиво (eager, непосредственно при чтении строки), лениво (lazy, только когда нужно посчитать количество полей) или очень ленива (very lazy, выделяется только запрошенное поле) — еще одна деталь реализации, скрытая от пользователя. Управление ресурсами. Мы должны решить, кто отвечает за совместно используемую информацию. Возвращает ли csvgetline исходные данные или делает копию? Мы решили, что csvgetline возвращает указатель на исходные данные, которые будут перезаписаны при чтении следующей строки. Поля будут созданы в копии введенной строки, и csvf ield будет возвращать указатель на поле в копии строки. При таких соглашениях пользователь должен сам создавать дополнительную копию, если какая-то конкретная строка или поле должны быть сохранены или изменены, и пользователь же отвечает за высвобождение этой памяти после того, как необходимость в ней отпадет. Кто открывает и закрывает файл ввода? Кто бы ни открывал вводимый файл,
он же должен его закрыть; парные действия должны выполняться на одном
уровне или в одном и том же месте. Мы будем исходить из предположения,
что csvgetline вызывается с указателем FILE, определяющим уже открытый
файл; по окончании обработки файл будет закрыт вызывающей стороной. Обработка ошибок. Когда csvgetline возвращает NULL, не существует способа отличить выход на конец файла от ошибки вроде нехватки памяти; точно так же и доступ к несуществующему полю не вызовет ошиб: ки. По аналогии с terror мы могли бы добавить в интерфейс еще одну функцию, csvgete г го г, которая сообщала бы нам о последней ошибке, но для простоты мы не будем включать ее в данную версию. Надо принять за постулат, что функции библиотеки не должны просто прерывать исполнение при возникновении ошибки; статус ошибки должен быть возвращен вызывающей стороне. Также не следует печатать сообщения или выводить окна диалога, поскольку функции библиотеки могут исполняться в системах, где такие сообщения будут мешать чему-то еще. Обработка ошибок — тема, достойная отдельного обсуждения, и мы еще вернемся к ней далее в этой главе. Спецификация. Все описанные выше решения и допущения должны быть собраны воедино в спецификацию, описывающую средства, предоставляемые csvgetline, и методы ее использования. В больших проектах спецификация должна предшествовать реализации, при этом, как правило, разные люди и даже разные организации создают спецификацию и пишут код. Однако на практике эти работы часто производят параллельно — тогда спецификация и код эволюционируют совместно; иногда же "спецификация" пишется уже после разработки программы, чтобы приблизительно описать, что же делает код. Самый грамотный подход — писать спецификацию как можно раньше и (как делали мы) пересматривать ее по мере реализации кода. Чем тщательнее и вдумчивее будет написана спецификация, тем больше вероятность создать хороший продукт. Даже при создании программ для собственного пользования важно подготовить достаточно осмысленную спецификацию, поскольку она требует анализа существующих проблем и четкого фиксирования принятых решений. В нашем случае спецификация будет включать в себя прототипы функций и детальное описание их поведения, сделанных допущений и распределения ответственности: Поля разделены запятыми.
Остаток параграфа посвящен новой реализации csvgetl i ne, которая COOT- | ветствует нашей спецификации. Библиотека разбита на два файла — заголовочный csv. h и файл воплощения csv. с. В заголовочном файле содержатся объявления функций, то есть представлена общедоступная часть интерфейса. В csv. с содержится собственно рабочий код библиотеки — реализации функций. Пользователи включают csv. h в свой исходный код и компонуют свой скомпилированный код со скомпилированной версией csv. с; таким образом, исходный код библиотеки никогда не должен быть видим.
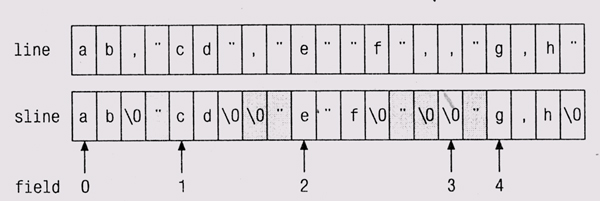
Эти объявления описывают простую структуру данных. Массив line содержит вводимую строку; массив sline создается путем копирования символов из line и вставки разделителя после каждого поля. Массив field указывает на значения в sline. На диаграмме показано состояние этих трех массивов после того, как была обработана строка ab, "cd", "e""f",, "g, h". Заштрихованные элементы в sline не являются частью какого-либо поля.
Поступающая строка накапливается в строке line, которая при необходимости наращивается, вызывая realloc; при каждом увеличении размер удваивается, как в параграфе 2.6. Массив sline всегда увеличивается до размера line; csvgetline вызывает split для создания в отдельном массиве field указателей на поля — этот массив также при необходимости наращивается. Мы привыкли начинать с очень маленьких массивов и увеличивать их по потребности, чтобы иметь гарантию, что код увеличения массива был выполнен. Если выделения памяти не происходит, мы вызываем reset для восстановления глобальных значений в их первоначальное состояние, чтобы дать шанс на успех последующему вызову csvgetline:
Функция endof line нужна для выявления и обработки ситуаций, когда вводимая строка заканчивается символами возврата каретки, перевода строки, ими обоими вместе или даже EOF:
Наш прототип использовал st rtok для определения следующего поля поиском символа-разделителя, которым в принципе является запятая. Однако при таком подходе невозможно обрабатывать запятые, находящиеся внутри кавычек. В split необходимо внести глобальные изменения (хотя ее интерфейс и не изменится). Представьте себе такие строки ввода:
Двойные кавычки внутри поля представляются парой смежных двойных кавычек; функция advquoted сжимает такую комбинацию до одной кавычки, а также удаляет кавычки, обрамляющие поле. Дополнительный код добавлен в попытке справиться с правдоподобным вводом, не подходящим под спецификацию, — таким, например, как "abc"def. В подобных случаях мы добавляем в конец поля все, что заключено между второй кавычкой и следующим разделителем. Оказывается, Microsoft Excel использует схожий алгоритм.
Наконец мы можем модифицировать тестирующую программу и проверить эту версию библиотеки: поскольку копия строки ввода сохраняется (чего в прототипе не было), появилась возможность распечатывать сначала исходную строку, а потом уже полученные поля:
Упражнение 4-1 При разделении полей возможно несколько уровней "ленивости" - -разделять сразу все поля, но только после получения запроса на конкретное поле, выделять только запрошенное поле и, наконец, разделять все поля до запрошенного. Рассмотрите потенциальные преимущества и недостатки перечисленных способов; реализуйте их и замерьте скорость работы каждого. Упражнение 4-2 Добавьте новые возможности в библиотеку. Сделайте так, чтобы: Упражнение 4-3 В нашей реализации библиотеки мы применили статическую инициализацию, используемую в С в качестве основы для одноразового переключения: если на входе указатель есть NULL, то выполняется инициализация. Можно, однако, сделать и по-другому: заставить пользователя вызывать некотору/ю специальную функцию инициализации — в ней, кстати, могут содержаться некоторые рекомендованные начальные значения для массивов. Попробуйте написать версию, которая объединяла бы все достоинства обоих подходов. Какую роль в вашей версии будет играть reset? Упражнение 4-4 Спроектируйте и реализуйте библиотеку для записи данных в формате CSV. Простейшая версия может просто брать массив строк и печатать их с кавычками и запятыми. Более интересный вариант — использовать форматные строки как printf. В главе 9 вы найдете некоторые полезные советы. |
|
|
|