|
|
|
Узкое место Нам хотелось бы начать с описания того, как мы избавились от узкого места в важной программе нашей вычислительной системы. Наша входящая почта поступала к нам через одну машину, называемую шлюзом (gateway), которая объединяла нашу внутреннюю сеть с внешним Интернетом. Электронная почта, приходящая извне, — в нашу организацию, насчитывающую несколько тысяч человек, приходят десятки тысяч писем в день — поступает на шлюз и затем передается во внутреннюю сеть; такое разделение изолирует нашу локальную сеть от доступа из Интернета и позволяет указывать адрес только одной машины (этого самого шлюза) для всех членов организации. Одной из услуг, предоставляемых шлюзом, является защита от "спама" (spam — мясные консервы, содержащие в основном сало), незатребованной почты, рекламирующей услуги сомнительных достоинств. После первых успешных испытаний спам-фильтр был установлен на шлюз и включен для всех пользователей нашей внутренней сети — и немедленно возникла проблема. Машина, исполняющая роль шлюза, уже несколько устаревшая и без того достаточно загруженная, была буквально парализована: поскольку фильтрующая программа работала слишком медленно, она отнимала гораздо больше времени, чем вся остальная обработка сообщений, и в результате доставка почты задерживалась на часы. Это пример настоящей проблемы производительности: программа была не в состоянии уложиться во время, отводимое ей на работу, и пользователи серьезно от этого страдали. Программа должна была работать гораздо быстрее. Несколько упрощая, можно сказать, что спам-фильтр работает примерно так: каждое входящее сообщение рассматривается как единая строка, которая обрабатывается программой поиска образцов с целью обнаружить, не содержит ли она фраз из заведомого спама — таких, как "Make millions in your spare time" (сделайте миллион в свободное время) или "XXX-rated" (крутые порно). Подобные сообщения имеют тенденцию появляться многократно, так что подобный подход достаточно эффективен, тем более что если какой-то спам проходил через фильтр, то характерные фразы из него добавлялись в список. Ни одна из существующих утилит сравнения строк — вроде д rep — не устраивала нас по соотношению производительности и возможностей, поэтому для спам-фильтра была написана специальная программа. Первоначальный код ее был весьма прост, он просматривал каждое сообщение и проверял наличие в нем заданных фраз (образцов):
Как можно сделать этот код более быстрым? Нам нужно искать в строке, а лучшим способом для этого является функция st rst r из библиотеки языка С: она стандартна и эффективна. Благодаря профилированию — технологии, о которой мы поговорим в следующем параграфе, — мы выяснили, что реализация st rst г такова, что использование ее в спам-фильтре неприемлемо. Изменив способ работы st rst г, можно было сделать ее более эффективной для данной конкретной проблемы. Существующая реализация st rst г выглядела примерно так:
На это есть несколько причин. Во-первых, strncmp получает в качестве аргумента длину образца, которая должна быть вычислена с помощью st rlen. Однако длина образца у нас фиксирована, так что нет необходимости вычислять ее заново для каждого сообщения. Во-вторых, strncmp содержит достаточно сложный внутренний цикл. В нем не только осуществляется сравнение байтов двух строк, но и производится поиск символа окончания строки \0 в обеих строках, да еще при этом отсчитывается длина строки, переданной в качестве параметра. Поскольку длина всех строк известна заранее (хотя и не в функции st rncmp), в этих сложностях нет необходимости, мы знаем, что подсчеты верны, поэтому проверка на \0 — пустая трата времени. В-третьих, strchr также сложна, поскольку она должна просматривать символы и при этом отслеживать \0, завершающий строку. При каждом конкретном вызове isspam сообщение фиксировано, поэтому время, использованное на поиск \0, опять же тратится зря, так как мы знаем, где окончится сообщение. И наконец, даже если решить, что strncrnp, strchr и strlen достаточно эффективны сами по себе, затраты на вызов этих функций сравнимы с затратами на вычисления, которые они осуществляют. Более эффективно выполнять все действия в отдельной аккуратно написанной версии st rst r, а не вызывать другие функции. Трудности подобного рода — обычный источник проблем с производительностью: функция или интерфейс хорошо работают в обычных ситуациях, но недостаточно производительны для нестандартного случая, а именно этот случай и является основным для решаемой задачи. Существующая версия strstr работала вполне удовлетворительно, когда и образец, и строка были достаточно коротки и менялись при каждом новом вызове, но когда строка оказалась длинной и при этом фиксированной, издержки оказались чрезмерно высоки. Исходя из вышеизложенных соображений, st rst r была переписана так, чтобы и обход строк образца и сообщения, и поиск совпадений осуществлялись прямо в ней, причем без вызова дополнительных функций. Поведение получившейся реализации было предсказуемо: в некоторых случаях она работала несколько медленнее, но зато в спам-фильтре — гораздо быстрее, и что самое главное, не встретилось случаев, когда бы она работала очень медленно. Для проверки корректности и производительности этой новой реализации был создан набор тестов производительности. В этот набор вошли не только обычные примеры вроде поиска слова в предложении, но и патологические случаи, такие как поиск образца из одной буквы х в строке из тысячи е и образца из тысячи х в строке с одним-един-ственным символом е, а надо сказать, что оба эти случая могли бы стать настоящей проблемой для непродуманной реализации. Подобные экстремальные случаи — ключевая часть оценки производительности. Наша новая st rst r была добавлена в библиотеку, и в результате спам-фильтр стал работать примерно на 30 % быстрее, чем раньше, — хороший результат для изменения одной функции. К сожалению, и это было слишком медленно. Чтобы решить задачу, важно задавать себе правильные вопросы. До сего момента мы искали самый быстрый способ поиска текстового образца в строке. Но на самом деле наша проблема заключается в поиске большого фиксированного набора текстовых образцов в большой строке переменной длины. Если исходить из этого, то наша st rst г не представляется, очевидно, лучшим решением. Наиболее эффективный способ ускорить программу — применить алгоритм получше. Теперь, когда у нас есть четкое определение проблемы, можно подумать и об алгоритме. Основной цикл
Разумнее было бы поменять циклы местами, обходя сообщение единожды — во внешнем цикле, а сравнения со всеми образцами осуществлять в параллельном или вложенном цикле:
Повышение производительности достигнуто на основании простейшего наблюдения. Для того чтобы выяснить, не совпадает ли какой-нибудь образец с текстом сообщения, начиная с позиции j, нам не надо просматривать все образцы — интересовать нас будут только те, что начинаются с того же символа, что и mesg[ j ]. В первом приближении, имея 52 буквы верхнего и нижнего регистров, мы можем ожидать выполнения только strlen(mesg)*npat/52 сравнений. Поскольку буквы распределены не одинаково — слова гораздо чаще начинаются с s, чем с х, — мы, конечно, не добьемся увеличения производительности в 52 раза, но все же кое-что у нас получится. Так что фактически мы создали хэш-таблицу, в которой в качестве ключей используются первые буквы образцов. Благодаря выполнению предварительных действий по созданию таблицы, определяющей, какой образец с какой буквы начинается, код isspam по-прежнему остался достаточно лаконичным:
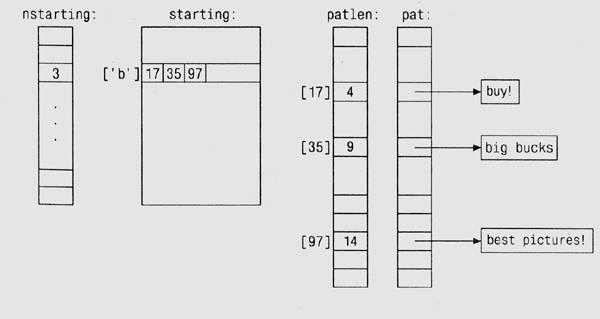
На приводимом ниже рисунке показаны эти структуры данных для трех образцов, начинающихся с буквы b.
Оставшаяся часть главы будет посвящена технологиям, используемым для выявления проблем производительности, вычленения медленного кода и его ускорения. Однако перед тем, как двигаться дальше, обратимся еще раз к спам-фильтру и посмотрим, чему же он нас научил. Самое главное — убедиться, что производительность имеет критическое значение. Во всех наших действиях не было бы никакого смысла, если бы спам-фильтр не являлся узким местом почтовой системы. Поскольку мы знали, что проблема заключается именно в нем, мы применили профилирование и другие технологии для изучения его поведения и выяснения главных недостатков. Далее мы убедились, что проблема сформулирована правильно и решать надо именно ее — глобально, а не концентрироваться на улучшении st rst r, на которую падало небезосновательное, однако же, неверное подозрение. Наконец, мы решили эту проблему, применив более удачный алгоритм, и, проверив, выяснили, что скорость действительно возросла. Поскольку она возросла в достаточной степени, мы остановились — зачем заниматься ненужными усовершенствованиями? Упражнение 7-1 Таблица, которая соотносит отдельный символ с набором образцов, начинающихся с него, стала основой существенного повышения производительности. Напишите версию isspam, которая использует в качестве индекса два символа. Насколько это будет лучше? Это — простейший особый случай структуры данных, которая называется "бор" (trie)'. Большинство подобных структур данных основаны на затратах места ради экономии времени. |
|
|
|